Overview
FPT.AI Reader provides users a powerful AI solution to digitalize all business documents in efficient and convenient way.
Business user can:
Apply well-built OCRs rapidly in the marketplace with high accuracy.
Build own new OCR for business specific documents with efficient building flow.
Use and manage OCR process, results.
Upgrade OCR's accuracy continuously during using period.
Integrate OCR results easily to other business systems.
Analyze OCR results in multiple dimensions.
User Guides
Types of usage
Basic: Quick use ready-to-use OCRs (which are already well-built with very-high accuracy)*
Advance: Build own new OCR
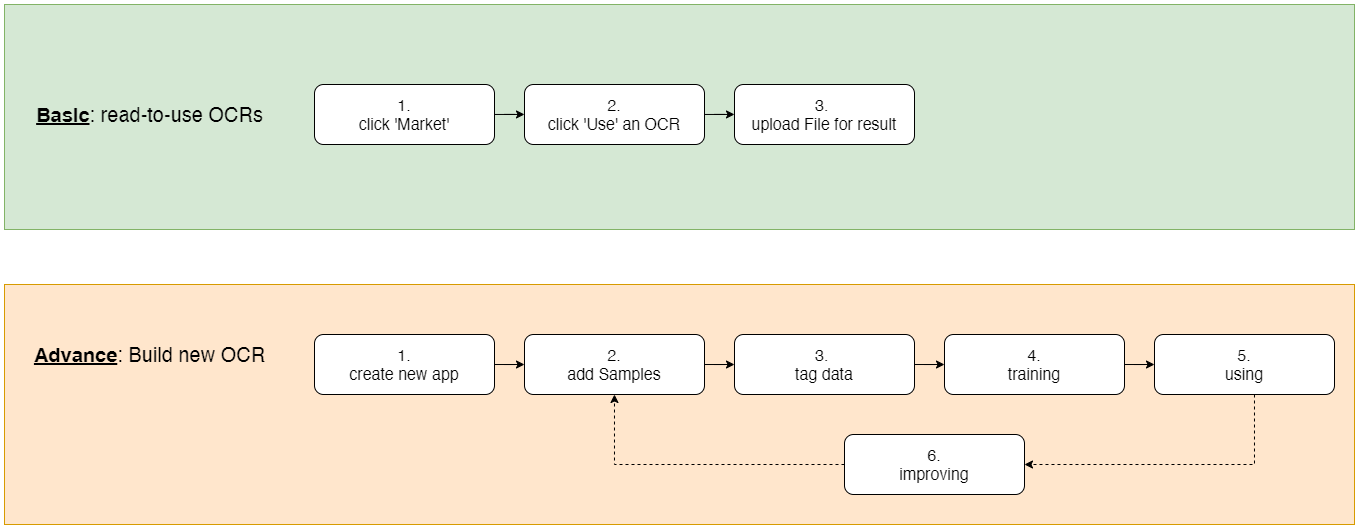
1. Basic: Ready-to-use OCRs (Marketplace)
1.1 Open Marketplace
On page "Dashboard":
- Click on button "OCR Marketplace" to open Marketplace
1.2 Browse Marketplace
On page "Marketplace":
Browse list of ready-to-use OCRs which grouped by Categories:
Personal docs
Insurance docs
Finance docs
Banking docs
General docs
Click button "Use" on a doc to start using it.
2. Advance: Build new OCR
2.1 Create
On page "Dashboard":
Click button "Add new"
Fill Creating popup:
Name: name of new application (ex: document name)
Type: processing type of application:
CROP app: main process is Cropping exactly document from original image (excluding irrelevant background)
Crop app could be used as first step of various OCR apps
Ex: "Card Crop" app could be used for OCR apps: ID card, Driver License card, ATM card...
OCR app: main process is Extracting required information from the document.
(Optional) While create OCR app, user has an option to select suitable CROP app
- This is not required if normally original images has not much irrelevant background (ex: scanned documents)
2.2 Train
Samples (sidebar menu "Samples"):
Add:
Click "Add New"
Select files
Click "Upload"
Tag:
Click one document on the uploaded list to expand its sections
Note:
Section "Original": is the original uploaded image
Section "Crop": is the cropped image (if the app has Crop function)
Section "OCR": is the extracted information (if the app has OCR function)
Section has:
Button "Edit": to edit Crop/OCR result
Button "Add to Train": to add the doc to Training dataset
Button "Review": to mark as reviewed
Click "Edit" to open page "Edit" and start tagging data
Note:
For Crop app: adjust Cropping area by updating its 4 corner points
For OCR app: use below tools to tag the reading selections and their actual texts
Button "Add selection": to add new selection which requires OCR reading
Use mouse to draw rectangle selection
Button a selection to add/update its:
'label' - name of the selection
'value' - actual text in the selection
button 'delete' - delete the selection
Button "Remove all selections": to remove all current selections
Button "Zoom" in/out: to zoom the image for easier tagging
Button "Rotate": to rotate the image for easier tagging
Button "Add to Train": to add the current sample to Training dataset
Training (sidebar menu "Training"):
Click "Train" to start training process
View Training history details in the following list
Click "Set Prod" to publish the trained OCR model to start Using
3. Managements
3.1 Results
Upload files need to be OCRs:
Via Web UI
Click "Upload"
Select files and upload
Via API
View OCR results on the following table
Export OCR results as file
Improve OCR (for new OCR only):
Click "Add to sample" on a document which not correct result
Go to page Samples
Update the added result sample with correct data (Crop/OCR)
Training and Using again
3.2 Permissions
User can share the OCR app with a team in different roles:
Role "Viewer": who can view only
Role "Editor": who can edit bot's Training data (for new-OCR app only)
3.3 Settings
3.3.1 Using Settings
Input:
Call API
Project
Webhook
Key
Usage
Output:
Export Excel
Export API
3.3.2 Training Settings
- (Premium User) Configure parameters for tuning Training model.