FPT.AIプラットフォームでCHATBOTの作成
4. NLPー自然言語処理
Botに顧客の質問が理解できるように教える。
NLPー自然言語処理 (Natural Language Processing)はFPT.AI Conversationプラットフォームの核心AI機能である。Botがユーザーのコメントを理解することができるようにbot作成者はbotに具体的な知識の量を教える必要がある。
その知識は下のように含む。
サンプル: 顧客が回答する要求がある問題について聞くために使用する文だ。
インテント: その質問目的と意図
キーワード: 文の中の重要な情報であり、Botはユーザーの言いたい問題が理解できて一つの適当な回答を出る。
エンティティ・タイプ : 先程のキーワードの意味を表すこと。
辞書: Botはインテントがもっと認証できるように代わりのワードと類義語を追加する。
例
| サンプル:2つの携帯電話を購入したいです** | ||
|---|---|---|
| インテント | キーワード | エンティティ・タイプ |
| buy | 2 | Quantity |
| 携帯電話 | Product |
注意:
chatbotにとってサンプルは非常に大切だ。それで、多ければ多いほどサンプルを追加するべきだ。サンプルの多様はchatbotがユーザーの様々な文を理解することに役立つ。
顧客の会話履歴に基づいて顧客の最も関心を持っているインテントが気になるべきだ。そして、そのインテントに多くのサンプルを多様化して追加する。
4.1 サンプルとインテント
サンプルはユーザーの偶然な文だ。各のサンプルは一つのインテントがある。Botにユーザーの多様な文を理解することを教えるために同じインテントでたくさんのサンプルを作成しなければならない。
インテントは、ユーザーが話す文の目的だ。インテントは、共通の目的と意味を共有する多くのサンプルで構成される。
システムにサンプルとインテントの入り方が2つある
1番目の方法: サンプルを手動で作成すること
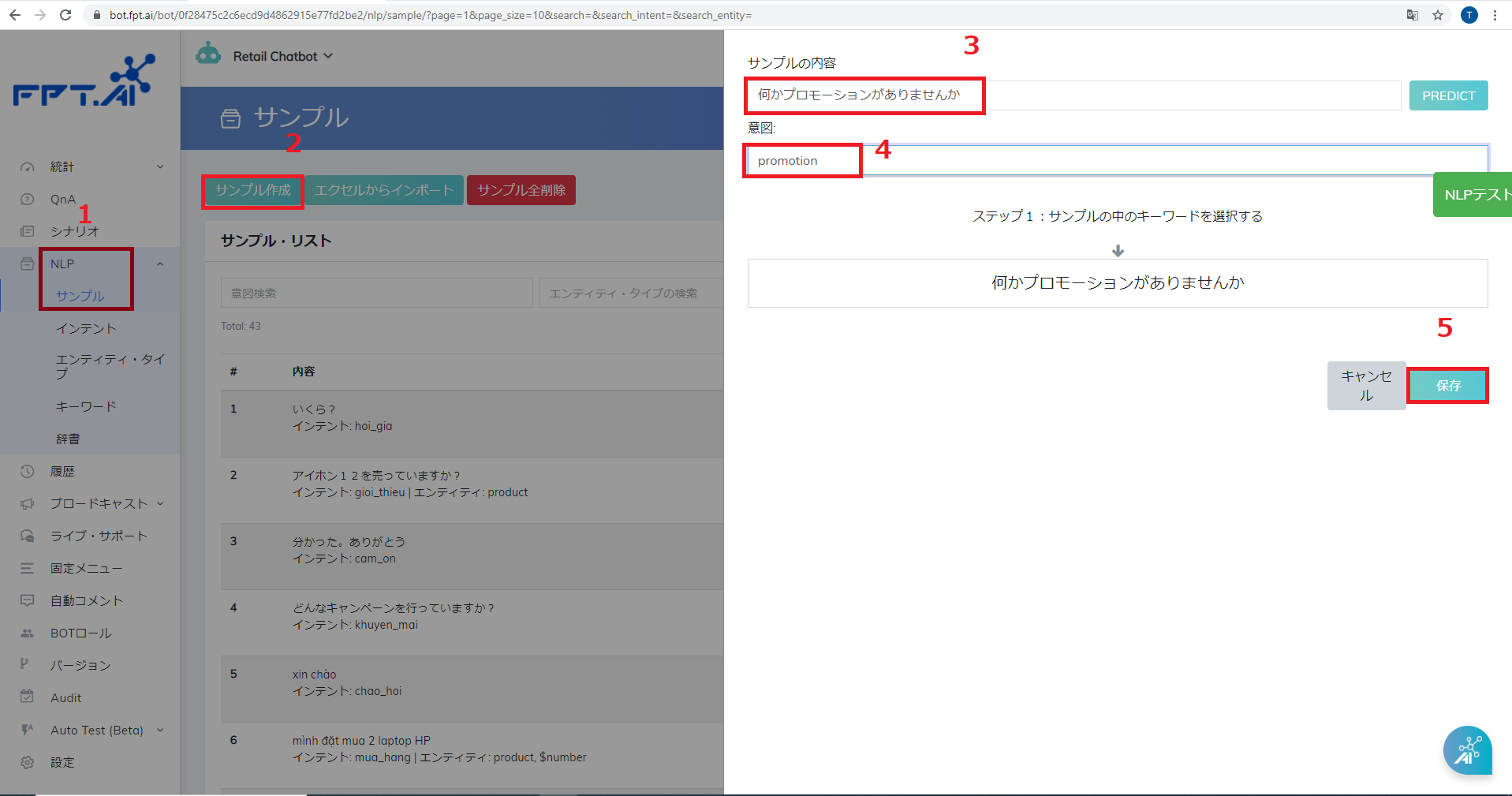
ステップ 1: NLPのセクションで 「サンプル」を押して (1) -> サンプル作成を選ぶ(2)
ステップ 2: サンプルの内容を入力する (3)
ステップ 3: 適当なインテントを作成する
ステップ 4: サンプルを完了するために「保存」をクリックする。
2番目の方法:エクセルからインポートすること
ステップ 1: NLPのセクションで「サンプル」を押して(1) -> 「エクセルからインポート」を選ぶ

ステップ2:準備しておいたエクセルファイルをアップロードするために「Browse」をクリックする
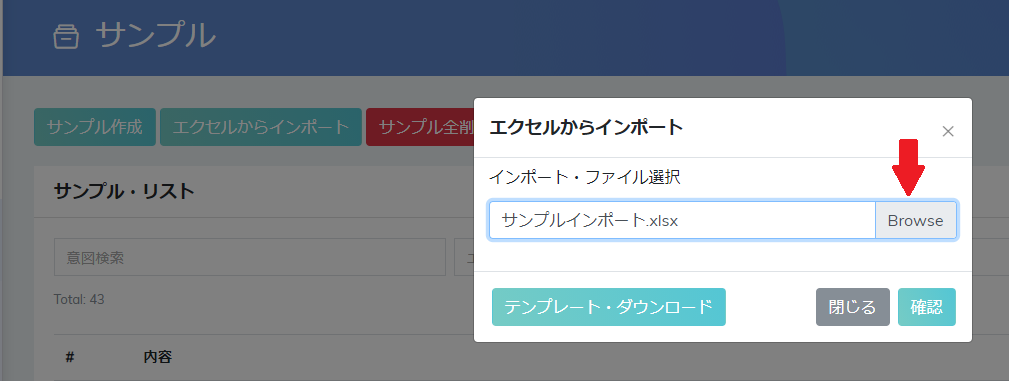
ステップ3:ファイルのアップロード完了するために「確認」をクリックする。
注意:
- エクセルのファイルにのサンプルとインテントを次のように書かなければならない。

インテントとサンプルのデータを作り終わった後、botはその新しい知識が理解できるように "学習" というボタンをクリックしなければならない。
インタフェースにある "NLPテスト" というボタンをクリックしてそのサンプルを入力して結果を見ることでBotはそのサンプルが理解できるかどうかテスト可能だ。
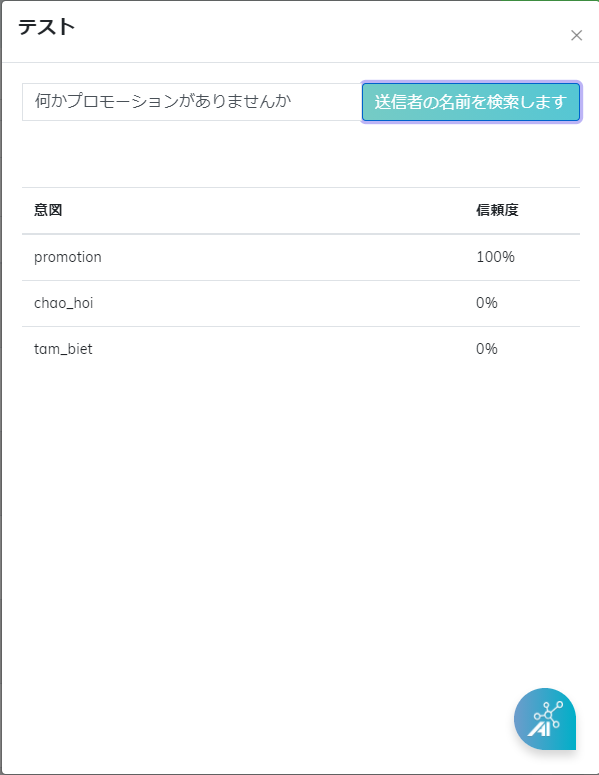
「インテント」というセクションでインテントを作成しておける。
ステップ1:NLPセクションでは「インテント」を選んでインテントの名前を入力する。 ステップ2:そのインテントの記述内容を入力します。Botがまだ回答を確認できない場合でその内容はBotのヒント文に表される。 ステップ3:済むために「インテント追加」ボタンをクリックする。
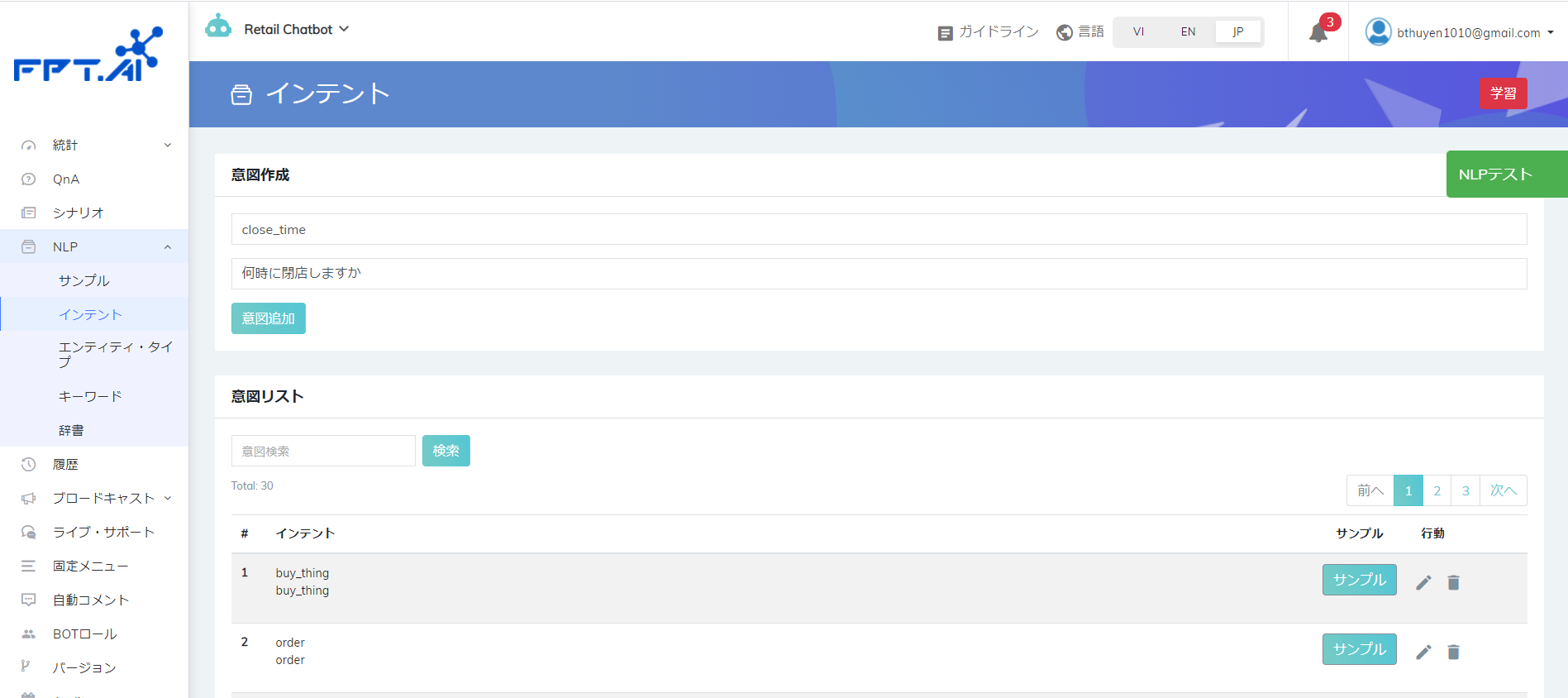
留意:NLPセクションでエクセルファイルから新しいサンプルを作成する時、インテントの記述を意味する文に書き直す必要がある。Botが回答の確認できない場合にインテントの記述内容はヒントの質問を作るのに使う。
4.2. キーワードとエンティティ・タイプ
キーワード(エンティティという)はサンプルの中の大切な情報で、Botの論理的な応答を決める。各キーワードは何か意味を表します。それはエンティティ・タイプと呼ばれる。
Chatbotの業務によって作成されるエンティティタイプが違う。
Chatbot FPT.AI Conversation は企業の業務に応じてカスタマイズをされた2種類のエンティティの概念を提供する。これらは情報エンティティと対象エンティティだ。
情報エンティティ
情報エンティティは通常でユーザーの情報となります。制御が難しくて多様な価値を含む。例えば、人間の名前、電話番語、証明書の番号等。このエンティティタイプに対して、予測一致か完全一致かという情報マッチング法を選択するべきだ。
例1: サンプル:静岡県まで商品を届けてください。電話番語は07041351818
- 上記のサンプルのインテントは「宅配」
- 上記のサンプルではスタッフさんはただしい人と正しい住所まで商品を届けるために2つの大切な情報がある。それで、静岡県は「address」というエンティティタイプを示すキーワードで、07041351818は「phone_number」というエンティティタイプを示すキーワードだ。
この例では、Botは顧客に応答するだけでなく、Bot管理システムに顧客の情報を保存する任務もある。このステップを行うために、bot設計者は情報通信手段としてJSON APIカードを使用する必要がある。
対象エンティティ
対象エンティティは通常で企業内で特定の業務、又は製品だ。このエンィティタイプは限度があり、Bot が認識できるようにユーザーはbotに十分なトレーニングデータが追加できる。エンティティタイプはChatbotの応答ロジックを決定する(同じインテントだが、様々対象に向ける)。
例:
サンプル:“アイホンXの値段はいくらですか“、” Samsung s9はいくら“
上記の2つのサンプルは値段を聞くという目的がある。それで、これらは同じ値段を聞くというインテントがある。
しかし、その2つの製品の値段は違う。そのため、正解回答を出すためにbotは2つの違い回答を出さなければならない。
結論:「アイホンX」と「Samsung s9」はキーワードと呼ばれる。それは2つの製品の種類だから、エンティティ・タイプは「製品」だ。
上記の例では、Botは2つの違う回答を出さなければならない。(対象のエンティティにより、回答を作成し方をご覧ください)
留意:
- Chatbotを設定する時、情報のエンティティはシステムで統合されておいたが、対象のエンティティは特定の需要が発生する時新しく作成される必要がある。
- エンティティ・タイプを確定することはBotの回答を作成することの前提だ。
4.3. エンティティマッチング法
タスクに応じて、FPT.AI Conversationプラットフォームで教えたエンティティ・タイプに通じてBotの作成者はbotがキーワードの理解についてトレーニングでき、または他の同じキーワードがもっと認証できる(機械学習の応用)。それは完全一致と予測一致という2つの情報マッチング法である。
4.3.1. 完全一致
完全一致の場合、Botはキーワードのリストの中にあるキーワードとエンティティ・タイプを調べる。
この方法は固定的なキーワードがあって前から確定できるシナリオによく応用する。
例1:“アイホンXの値段はいくらですか”、“Samsung s9はいくら?”
上記の2つの文に“製品”というエンティティ・タイプは“アイホンX”と“Samsung s9”でchatbotは完全一致という方法をやる。
例2:保険会社は様々な保険の種類がある場合
- 「健康保険」、「事故保険」、「自賠責保険」などはキーワードだ
- 「保険種類」はエンティティ・タイプだ。
Botがサンプルから情報をマッチングできるように、完全一致という情報マッチング法によってキーワードとエンティティ・タイプをマークする必要がある。
ステップ1:NLPセクションで、サンプルをクリックしてキーワードとエンティティ・タイプをマークする。
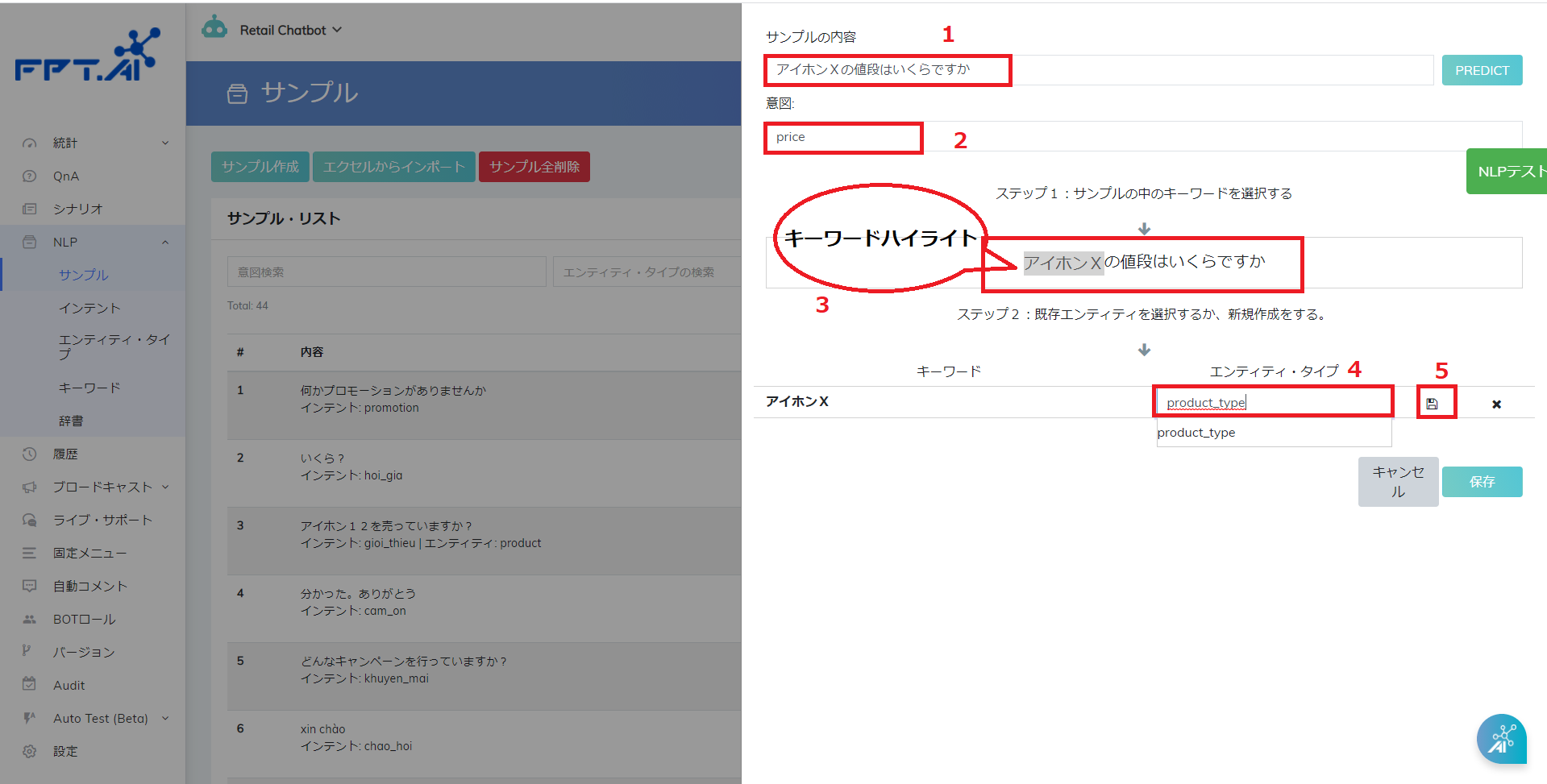
ステップ2:NLPセクションでエンティティ・タイプをクリックして情報マッチング法を完全一致に直す。
ステップ3:キーワードセクションで、システムはサンプルセクションにキーワードハイライトを保存した。ここで、botはユーザーのインテントが認証できるように略語などの類義語を追加する可能だ。
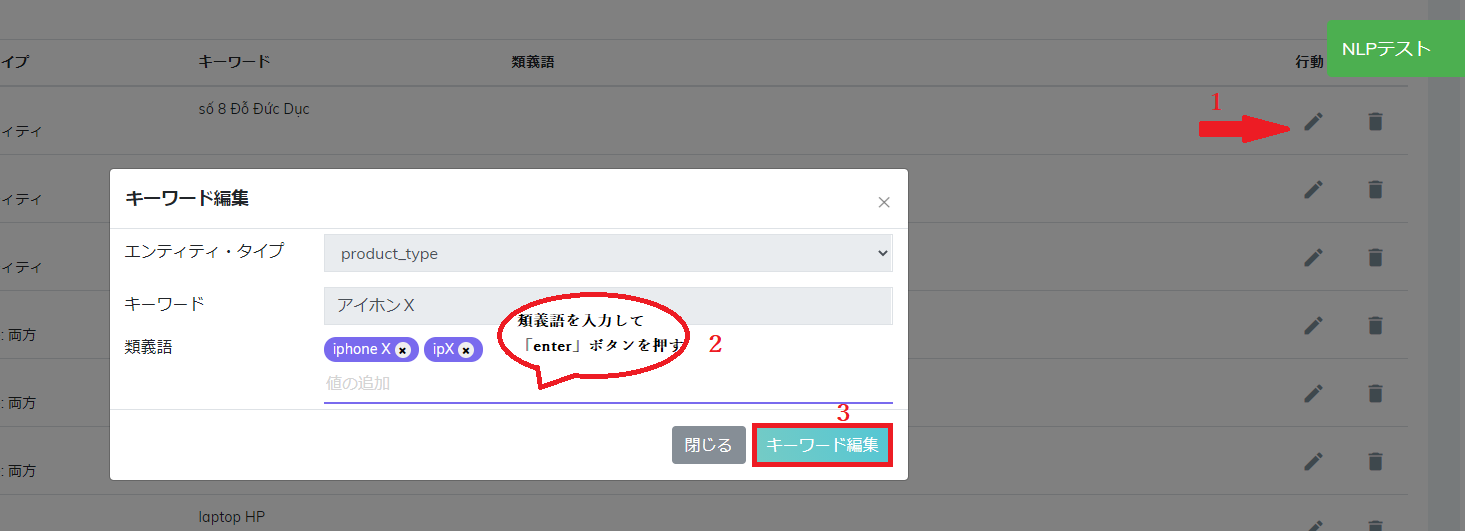
ステップ4:新しいデータを作成するために学習をクリックする。
ステップ5:成功にトレーニングした後、Botのエンティティ・タイプを認証可能を確認するためにNLPテストというボタンをクリックする。
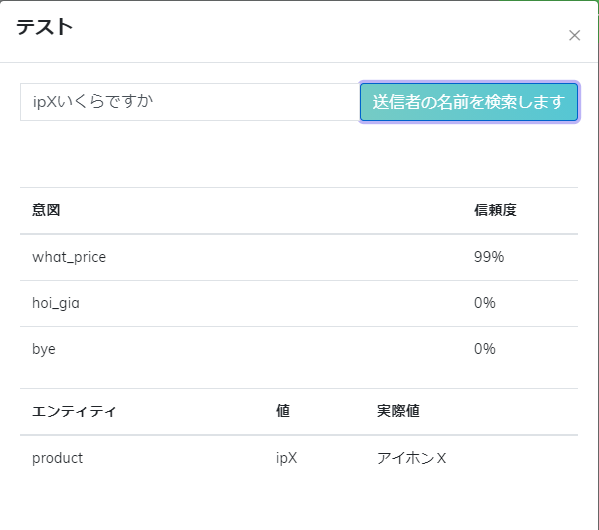
トレーニングされた後、Botは「ip X」とは「iphone X」だと理解できる理由は製品のデータがありましたのだ。トレーニングした類義語とキーワードリスト以外の文と製品をテストする場合なら、Botが認証できない。
実際値とはキーワードリストにある固定値だ。これはキーワードに応じてBotの回答を作成するのに使われる値です。詳細は数条件のチェックで見る。
4.3.2. 予測一致
Botが機械学習によってエンティティの情報を調べるから、タグ付けされたキーワードとエンティティ・タイプが多ければ多いほどよい。Botは他の情報を予測するためにキーワードをタグ付けしたサンプルを使用する。しかし、完全一致と比べると固定値のリストで検索しない。
この方法は前から確定できない情報によく応用する。例えば:人の名前や電話番号と住所など
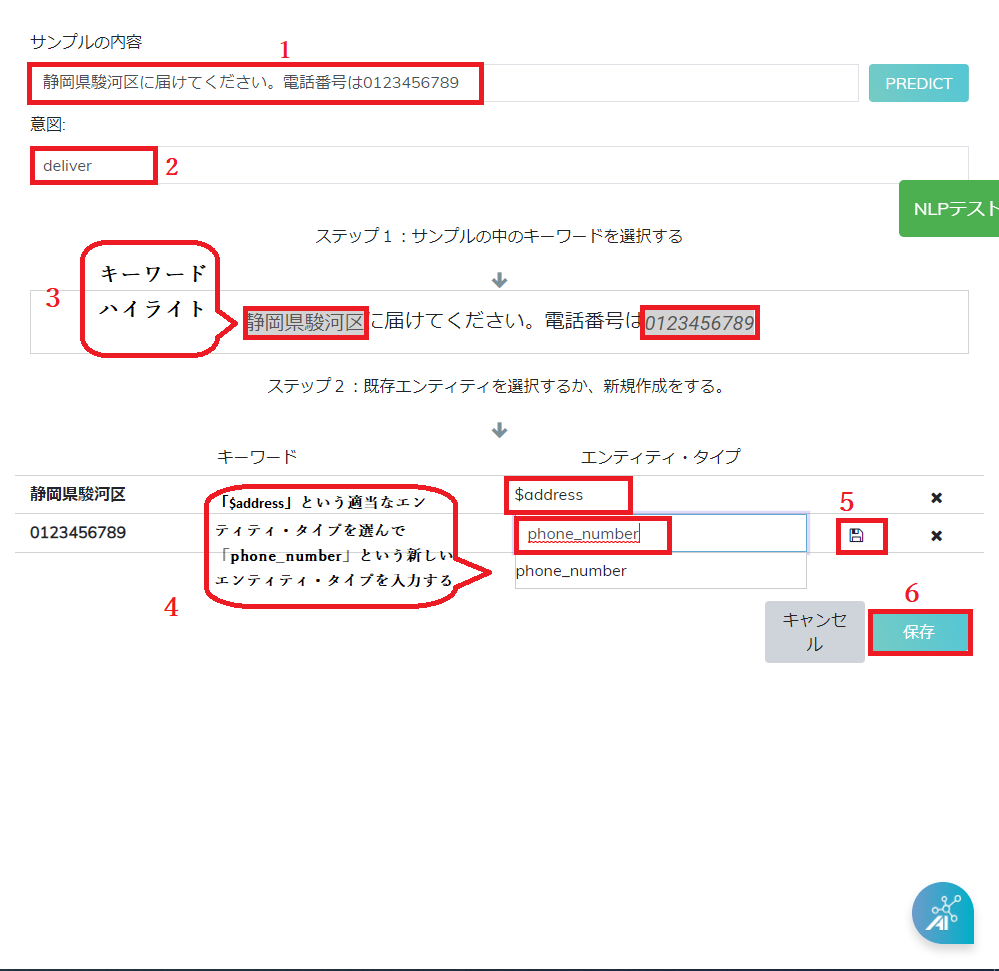
例:静岡県駿河区に商品を届けてください。電話番号は0123456789
「静岡県駿河区」と「0123456789」という情報のエンティティは予測一致の情報マッチング法を使用する例だ。
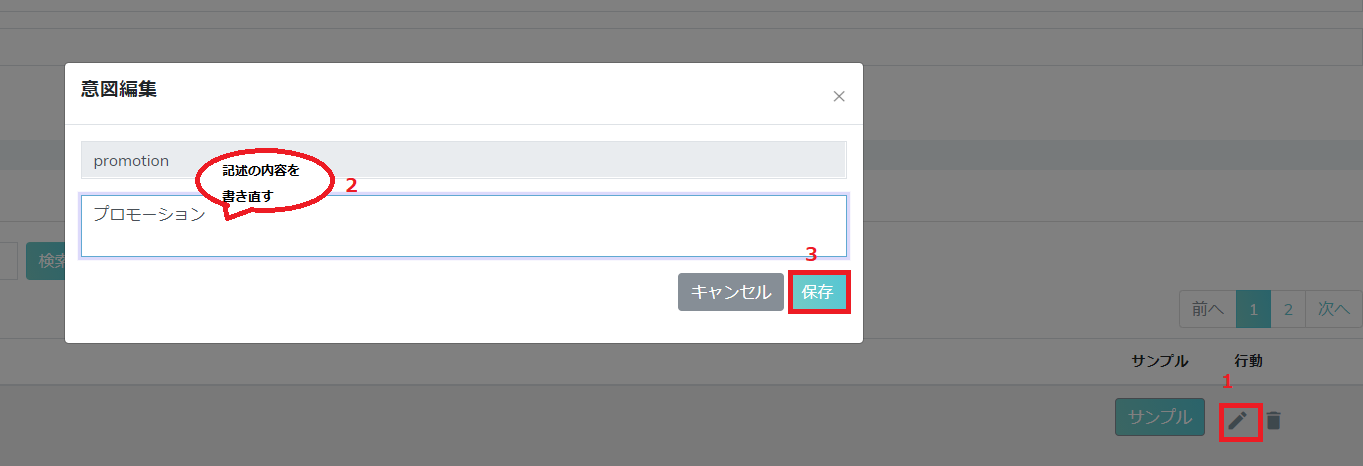
ステップ1:大切な情報のエンティティを含むサンプル(1)を入力する。インテント(2)を選んでキーワード(3)ハイライトして適当なエンティティ・タイプ(4)を選択する。
他の情報に対して、新しいエンティティ・タイプを入力して「保存」(6)をクリックする。
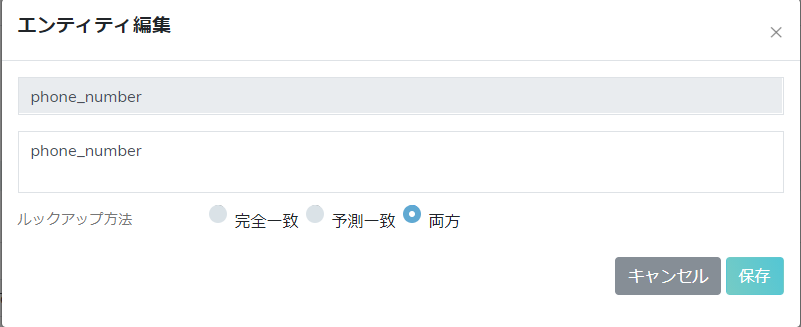
ステップ2:NLPに入り->エンティティ・タイプ->エンティティ編集を選ぶ。「phone_number」のエンティティ・タイプを「予測一致」に変化するかそのまま「両方」が維持できる。
ステップ3:キーワードの類義語の追加する他の情報マッチング法と違うのは予測一致という情報マッチング法がエンティティを認証するために機械学習を使用する。それで、Botに何のエンティティ・タイプか認証できることをトレーニングするために、同じ形式で多くのキーワードをタグ付けする必要がある。
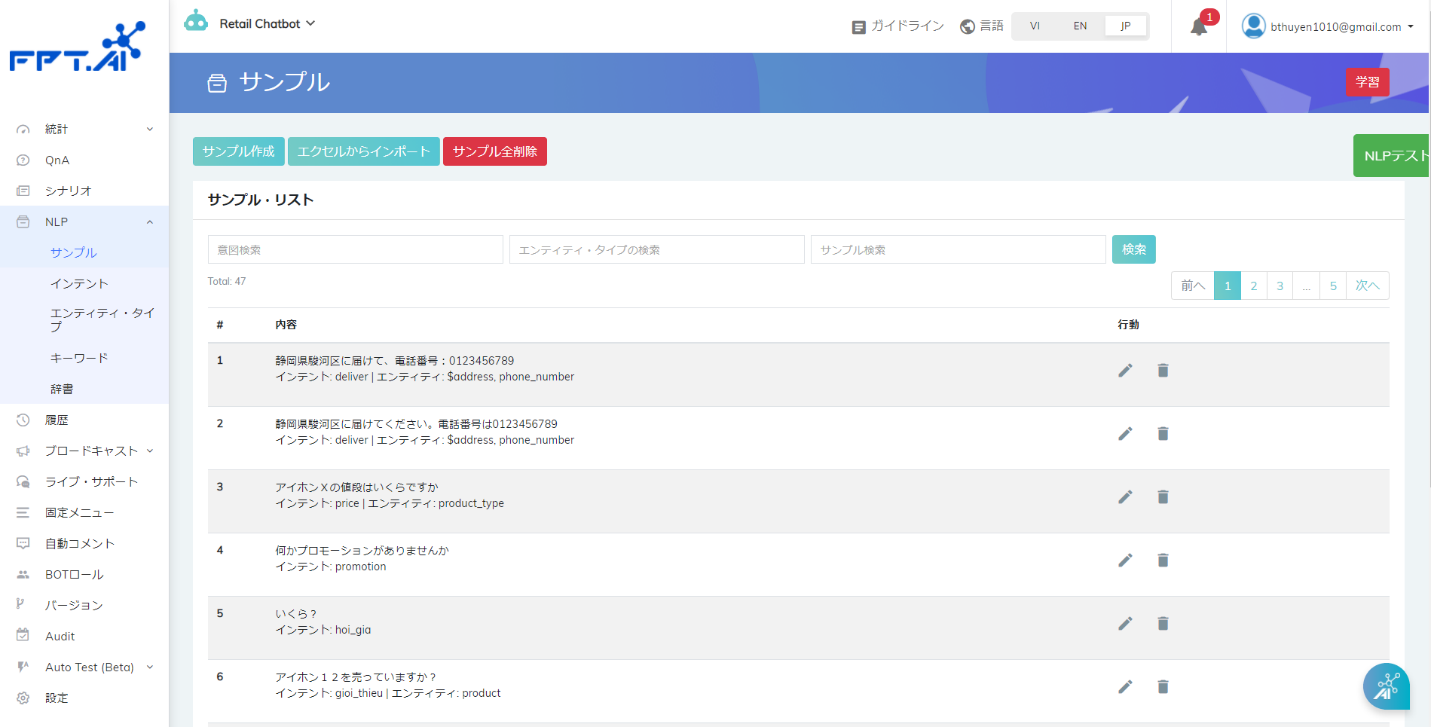
ステップ4:Botにアップデートしたばかり情報のエンティティ・タイプを教えるために「学習」をクリックする。
ステップ5:インタフェースで「NLPテスト」のクリックで結果をチェックする。それから、Botにトレーニングした電話番号と違う数字を入力してBotはそれが「phone_number」というエンティティ・タイプが認証できる。
4.4 辞書
サンプルの多様さを追加する代わりに、辞書にサンプルにある言葉と句の代わりのワードや類義語を追加する可能でBotの認証可能のより正確になる。
留意:そのチャットボットの特性が必要な場合にのみ、辞書を使用する必要がある。 例:身分証明書は身分証、マイナンバーカード、住民基本台帳カードなどの代替単語がある。NLPチャットボットへの干渉を引き起こすケースを制御することは難しいため、辞書の使用を制限する。
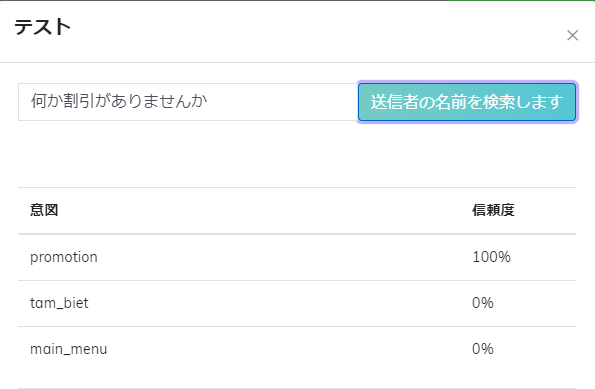
例えば:「promotion」のインテントにサンプルリストがある
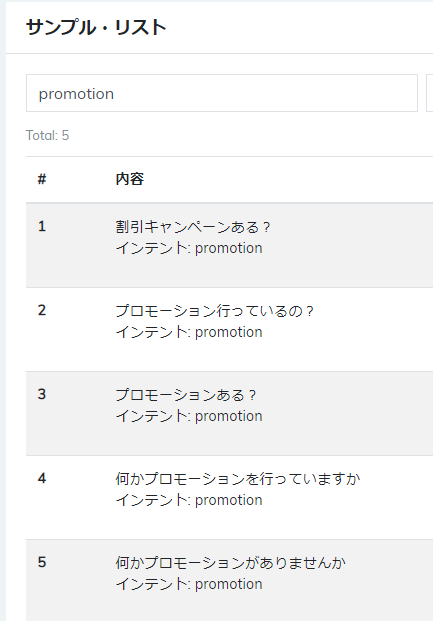
同じインテントで新しい文を処理する時、Botはインテントを正しく認証するが信頼度が低いです。Botの理解レベルを改善するために同じ「promotion」インテントでたくさんのサンプル追加する必要がある。例えば:「割引ある」、「プロモーションまだ行っているの?」、等。または、「プロモーション」の代わりのワードとして「割引」が追加できる。ユーザーが「割引」を含む文を使用する場合、Botはユーザーがプロモーションについて聞きたいと理解できる。
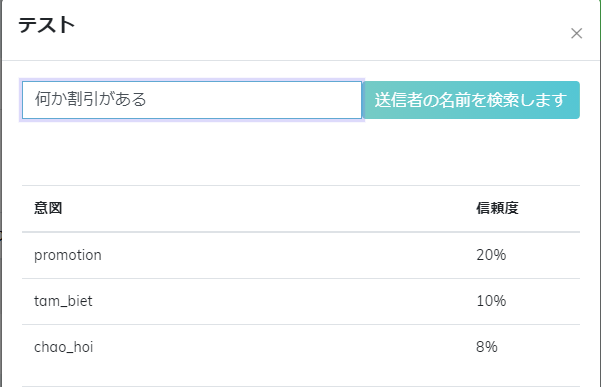
辞書で類義語と代わりのワードを入力した後、Botに教えるために「トレーニング」をクリックする。
Botのトレーニング結果を評価するためにNLPテストします:信頼度が高くなったことで正確に認証する。